
Management of risk is not a simple undertaking but is essential for enterprise governance and decision making. Whether a company is adopting an enterprise risk management framework (e.g., ISO 31000, COSO, or NIST RMF) or building out an information security management program (e.g, ISO 27001 or NIST Cybersecurity Framework), you will have to identify and assess risks. Depending on the framework a company is utilizing, there can be quite a few steps associated with the entire process; an information security risk assessment is one of the key steps that often presents challenges.
It’s intuitive for security professionals to identify common risk areas. If you open a popular news site that covers information security topics on any given day, your odds of seeing something trending with ransomware, third-party compromises, or phishing attacks are high. Most professionals could likely create a similar list of the potential loss events associated with those risk areas (at a high level). However, if you gave that same group of professionals a chart between 1-5 and asked them to mark how much risk each of those areas posed or how much money they might lose from such an event, you’d likely get a different answer from each professional.
This isn’t to suggest that rating risk on a scale from 1-5 is the only way to do it, or that there shouldn’t be differences in the risk levels. There should be. It’s to help demonstrate how much more complicated risk management can become when you get beyond identification. For that reason, LogRhythm Labs wanted to highlight risk assessment in information security to give people an understanding on the subject, and how information security professionals can use tools to help them along the way.
Basic Security Risk Assessment Steps
Define an Approach
As mentioned above, there can be variations in the steps and verbiage amongst the different frameworks, so it’s critical to define the factors you will be using as a part of your risk assessment, or what NIST 800-30 refers to as the “Risk Model.” These factors typically include threats, vulnerabilities, impacts, likelihood, predisposing conditions, or further decomposed into loss events, threat sources, and threat maturity. Creating and defining a risk model will alleviate misunderstandings and challenges by defining a common framework people can use to talk about risk in the same way.
Security Risk Assessment Methods
After establishing a model, determine what kind of assessment you will perform. You can do a qualitative assessment (using a system assigning a descriptor to represent a scale of risk) or quantitative assessment (using a system of numerical values calculating probabilities of potential gains or losses because of the risk). These security risk assessment methodologies are often combined as they each have strengths and weaknesses.
Quantitative vs. Qualitative Security Risk Assessment Methods
Quantitative methods tend to benefit when the question is a cost-benefit scenario that can measure the effectiveness of multiple types of risk mitigation strategies as the analysis lends itself to be repeated. However, quantitative methods are not completely free from subjectivity and levels of uncertainty and the calculation of values can make projected risk values too wide for use. Additionally, the time and effort to come to these quantified calculations may not be worth it.
Qualitative methods are beneficial when sorting and prioritizing risks against each other. However, this method tends to compress the overall scale using descriptive language (low, medium, high). This compression can make prioritization of risk difficult when there are many risks that are documented. Also, without detailed examples and rationale, assessed risk levels are prone to be wildly different depending on the person making the assessment.
Using SIEM to Enhance Your Security Risk Assessment
Let’s dive into a detailed example covering why and how to perform an information security risk assessment:
Premier Branding is an invented global marketing and analytics firm headquartered in Chicago, Illinois. Premier has become a global powerhouse in the marketing industry by acquiring smaller firms across the US, Europe, and Asia.
Premier Branding’s “risk register” is not up to date, there has been historically limited information security involvement, and assessments have largely been rolled forward since going public three years ago. After repeated audit findings related to inappropriate risk management, they have dedicated resources to a revamp the process. The CISO, Zee Roe Truss, has noticed that phishing campaigns have been notably on the rise in the industry in hopes of gaining initial access to exfiltrate sensitive customer data.
Zee noted the vast number of acquisitions have occurred so rapidly that most customer databases that contain detailed information such as company name, key contacts, addresses, purchase history, and data related to their analytics are disparate across the globe. However, large reference accounts are located on a single globally available database for employees in various countries to work together. These Fortune 500 customers are critical to the continued success of Premier Branding and would respond very negatively if their business or associated data was compromised. Zee presents this information to the risk team which includes InfoSec Manager, Burp Sweet, to ensure that it’s given appropriate consideration.
Given Zee’s information, the risk team has gathered and is now assessing information security risks. The team has identified a need to determine the level of risk associated with external malicious actors impacting the confidentiality of customer data in the reference accounts database via a phishing attack.
Security Risk Qualitative Assessment Example
Let’s say the Premier risk team has chosen to use a qualitative approach to determine the level of risks during their assessment. One of the most commonly identifiable scales is a five-level scale of risk (Figure 1), adapted from NIST 800-30, Guide for Conducting Risk Assessments.
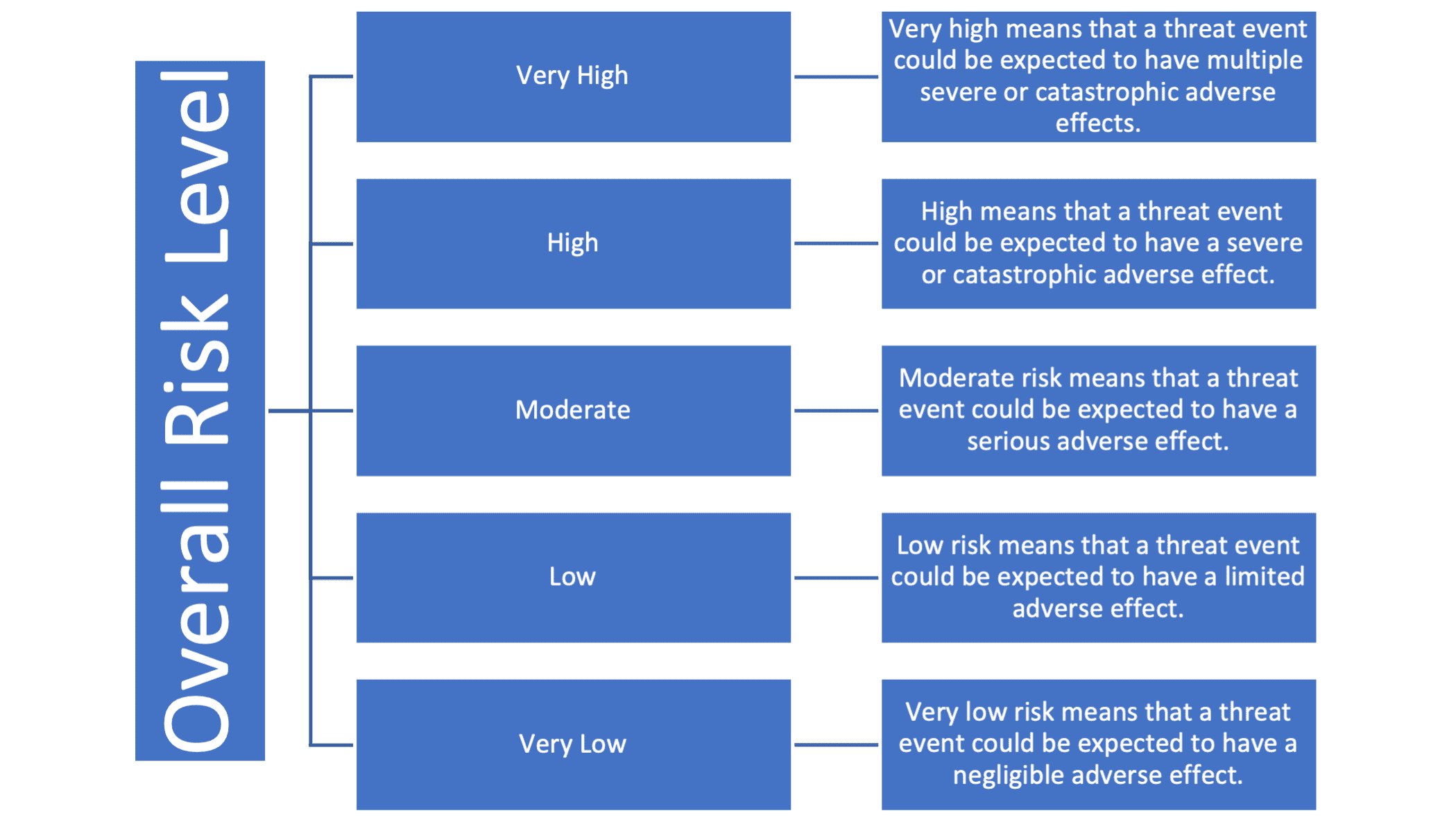
To calculate that level of risk, we’ll utilize NIST SP 800-30 again, which breaks down how the overall risk level is achieved as a calculation of the level of impact and the likelihood of occurrence on the same five-point scale. This heat grid is likely what most folks are familiar with seeing in existing risk assessments (Figure 2).
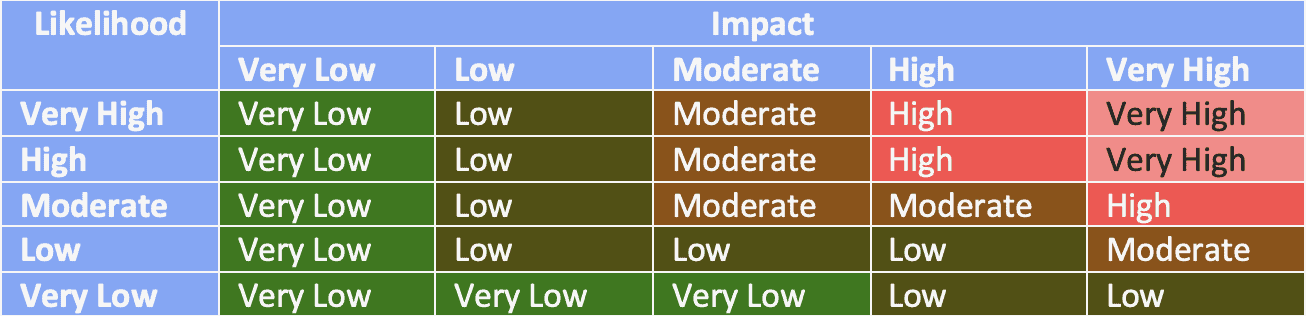
Calculating Impact of the Risk Assessment
Through interviews with key business leaders, the risk team determined that leaked information could have a severe or catastrophic impact to the Premier Branding business. Over 60 percent of the revenue comes from reference accounts and reputation is one of the biggest factors for winning that business. The database contains over 250 companies and 2,000 individuals that could be personally identified with their information. Additionally, information contained in that database would have privacy compliance implications (such as General Data Protection Regulation) in several countries and could be subject to large fines and sanctions.
Calculating Likelihood of Risk Event
After interviews with technical leadership teams, there was very little concern over the perceived increase in phishing attacks and compromised data. The teams frequently patch systems, perform annual anti-phishing training, and conduct change management processes. It’s determined that this likely would be a low or very low likelihood. However, the risk team wanted to get further input from Burp’s security team.
Burp went to his security operation center (SOC) team and wanted to know more about what they had seen in the way of trends on phishing campaigns against technical users or activity targeting the reference customer database.
Analysts observe regular phishing attempts and very few successful (about 1 out of every 80 attempts).
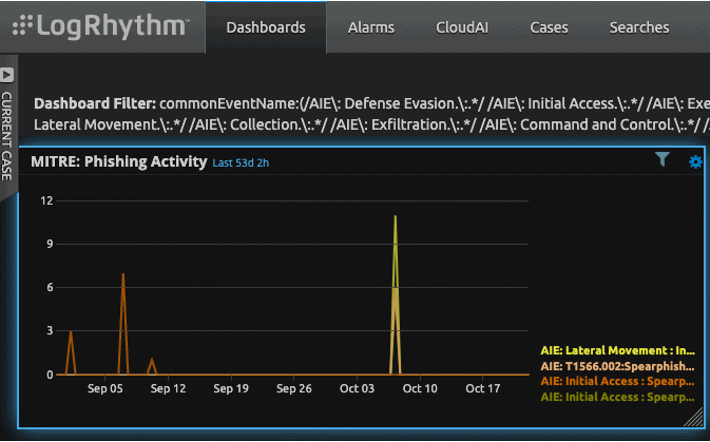
Additionally, the team ran investigations in the security information and event management solution (SIEM) on successful phishing attacks and noted there has been a trending increase in volume as compared to the prior 5 years (Figure 4). No exfiltrations had been detected against the reference customer database since its creation five years ago.
Because Burp knew there were successful phishing attacks occurring (increasing in frequency) and because it’s needed by many people around the globe, it does not have particularly strict access controls. While no phishing attempts have had an adverse impact of the customer reference database yet, Burp and the risk assessment team, believe the likelihood to be moderate given the history of attempts against that database, lax access controls, and trending phish conditions.
Assessing the Final Risk Rating
Given the very high impact and moderate likelihood ratings, the overall risk of external malicious actors impacting the confidentiality of customer data in the reference accounts database via a phishing attack is given a high rating. The risk response developed because of the high-risk rating includes tighter access controls (e.g., timely removal and least privileges) on the database and additional phishing and awareness trainings to ensure employees are as adequately prepared as possible. End of story, right?
The assessment team made their presentations to executive committee about the updated risks, assessments, and suggested responses. Being a global company there is no surprise the final risk chart resembled a 50-year-old dart board as opposed to a clean color-coded grid. With over 20 risks that are rated high and very-high mostly around information security, with suggested mitigating actions that cost in the hundreds of thousands of dollars, the board has requested more granular priority to address these critical risks.
This is not an uncommon challenge when it comes to risk assessment, especially at large organizations where the number of risks is excessive. Which one is the most urgent and how far a company’s dollar will go in limiting the potential impacts of the risks are very important questions and qualitative ratings make them difficult to answer. At this stage, a hybrid approach could be taken as risks that were presented to the board are “ranked” highest to lowest by risk level. The team could perform a more granular quantitative analysis on just the high and very-high rated risks (those that had recommended mitigating responses). A full quantitative analysis could have been performed across all risks, however, there is a decent chance it would have taken longer and may not have yielded any different actionable results.
Security Risk Quantitative Assessment Example
Using the same scenario as last time, let’s say the Premier Risk team had decided that they would proceed using a quantitative assessment method so that decision makers could use values that will help them calculate risk mitigation strategies. Instead of choosing to define their own methodology, the team has chosen to use the Factor Analysis of Information Risk (FAIR) methodology created by The Open Group (recommended by NIST).
FAIR risk ontology prides itself on modeling all types of risk scenarios using a common language (dollars) to demonstrate how much risk is present for a given risk scenario that all business leaders can understand. Risk scenarios defined in FAIR must include an asset, threat actor, and threat effect. Once a risk scenario is defined, analysts must determine a minimum, maximum, and most likely number for how many “Loss Events” they can expect on an annual basis and how much they could expect to lose for each of those events (Figure 5). Then, using Monte Carlo analysis on those figures, a forecast of how much money could be lost on an annual basis will be produced.
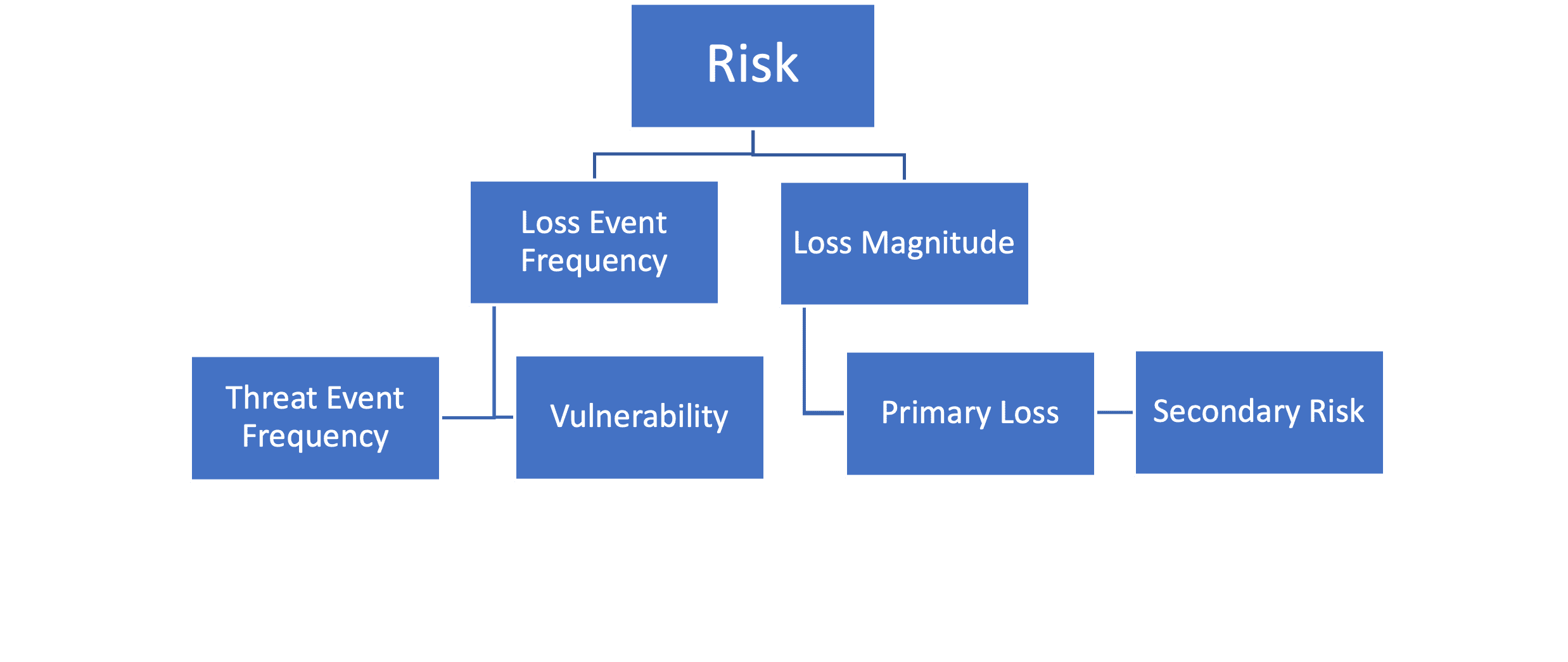
As defined in the initial scenario, the risk team appropriately defined the risk scenario with the asset being the customer data in the reference accounts database. The threat actor is the external malicious actor(s), and the threat effect is the compromise of the confidentiality of the reference customer database via a phishing attack.
Calculating Loss Event Frequency (LEF)
To determine a minimum, maximum, and most likely figure for how many times in a year you will experience a loss event is a difficult task for many risk scenarios. However, FAIR allows you to calculate that value by breaking it down into threat event frequency or how often the threat event will occur but not necessarily end in a loss event, and vulnerability (which is a percentage value of how many threat events will result in a loss event). Both threat event frequency and vulnerability can be broken down further in FAIR, but for the sake of our calculation and the scenario presented, we can likely estimate reasonably accurate ranges. A key component of FAIR ontology for estimates with uncertain conditions is that an accurate range is more important than a precise or smaller range.
Given what we saw with the last five-year report on phishing attempts, we can see that the smallest number of phishing attempts that occurred was 1 and the highest was 24. Given most years were around a dozen attempts, we can reasonably project the attempts to most likely be 12 as well. Because the number of attempts changes over time, we would give this range a low confidence. To calculate our vulnerability, we could break down the calculation by threat capability and resistance strength but given the information we received from the SOC team that only 1 out of every 80 attempts has resulted in a successful phish, we could reasonably assume 5% of phish attempts would be the max, 1% to be the most likely, and 0% to be the minimum.
Calculating Loss Magnitude (LM)
Loss can be categorized into one of six categories in FAIR: Productivity, Response, Competitive Advantage, Replacement, Fines/Judgement, and Reputation. These losses can be primary (losses incurred as direct result of the loss event) or secondary (losses from secondary stakeholders that come as a reaction to the loss event).
Given these categories and what we know, we should evaluate the forms of loss. For productivity considerations, there is likely no loss here. As no systems responsible for sales or salespeople would be affected in this scenario, no productivity losses would be incurred. For response losses, the risk team in their interviews determined that in the event of a confirmed breach of the reference accounts database, a third-party firm would have to be engaged to perform an analysis on data stolen, investigations of this scale, cost $75,000 on the low end, $150,000 on average, and $300,000 on the high end. The risk team determined that no competitive advantage loss would be incurred as no competitor is obtaining trade secrets, M&A, etc. Additionally, no replacement costs would be associated with this as no theft or physical damage that would require replacement. The risk team in interviews determined that there would be the potential for secondary fines and judgments associated with this breach as personal identifiable information (PII) would be disclosed. The global compliance team has estimated that a breach of the reference accounts database with that many users could result in a fine from $100,000 on the low end, $250,000 on average, and $500,000 on the high end. The last category of loss is reputation, which is likely the biggest potential loss for this risk. As the risk team determined before, 60% of the company’s 350 million in revenue is from these accounts and the sales team estimates a loss of 1-3% of those customers deals. This results in a low-end loss of 2 million, 4 million most likely, and a little over 6 million at most.
Determining Annual Loss Exposure (ALE)
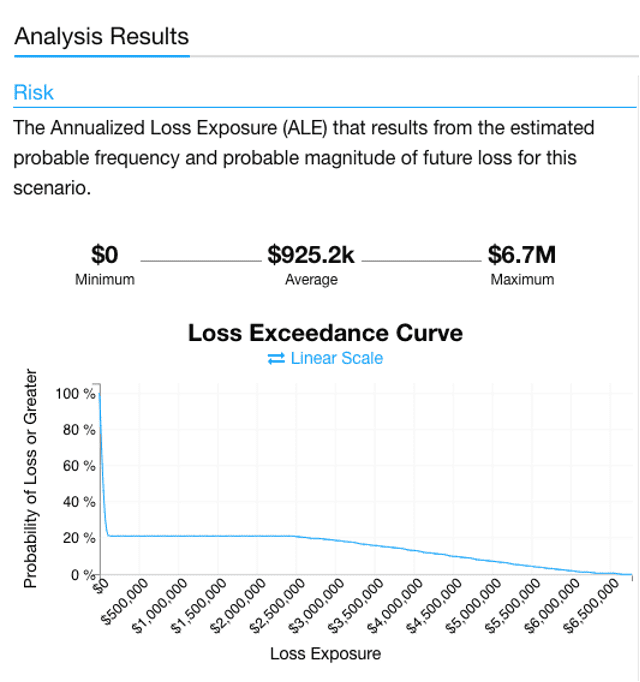
When the analysis is run the Premier team ended up with a graph like the one shown here (Figure 6). A minimum of zero dollars, a max of 6.7 million dollars, and an average cost of $925,200. The important distinction here is that this is not a prediction that Premier Branding will annually experience a loss of $925,000, but a probabilistic model that shows an average cost of this risk annualized. The loss exceedance curve gives this more context in visualizing what percentage of scenarios resulted in losses. In nearly 80% of the scenarios there was little or no loss. Additionally, you could rerun these scenarios with various solutions and controls to see how much you could lower your risk.
Key Takeaways on Information Security Risk Assessment
While the scenario crafted above has been highly simplified for the sake of demonstration, it doesn’t take away from two key points:
First, each method of assessment has benefits and drawbacks that should be considered when determining which method will provide the most value to you and your stakeholders. While we used both methods in a hybrid form with the same scenario, Premier Branding had many risks, but also had the resources and knowledge to implement a more complex quantitative analysis after initially ranking the risks.
Second and perhaps most importantly, the data and knowledge you have in your own environment is highly informative. Industry data and trends can be useful, especially when there is little to zero starting points, but when it comes to calibrating and estimating the specific risks in your environment, use the information you have at your disposal. Start with appropriate stakeholders, then reference and cite system data coming from your environment (e.g., SIEM, vulnerability management, asset management). While these tools may not have been designed for the purposes of risk assessment, they can contribute additional value in the process.
Additional Resources for Assessing Information Security Risk
- NIST
- COSO
- FAIR
- RiskLens
- Cyber Risk Management Service Provider
- *The above graph was generated using RiskLen’s FAIR University tool with the contrived data for the example scenario. Use of RiskLens and or the FAIR-U tool is subject to their terms and conditions and licensed only for non-commercial uses.