
What is a Zero-Day Exploit? What Can be Done About Them?
In cybersecurity, a zero-day exploit refers to the method a hacker uses to take advantage of a security vulnerability in a computer system, software, or network. When a zero-day vulnerability is discovered, both defenders and hackers rush to either mitigate or exploit it. The term “zero-day” indicates that the security vulnerability is being exploited or targeted as soon as discovered, giving IT and security teams zero days to prepare or patch the vulnerability.
Cybercriminals constantly target vulnerabilities in Microsoft Exchange; therefore, zero-day exploits will continue as new attack methods are always on the horizon. What can be done to proactively detect zero-day exploits before they become known? It comes down to detecting unusual or suspicious activity that would tip off an analyst to an attack.
Why It Is Important to Monitor Zero Day Exploits?
Cybercriminals commonly attempt to compromise enterprises before zero-day patches are implemented and advanced attackers will exploit zero-day vulnerabilities before they are even known. For example, in September of 2022, Microsoft announced “Reported Zero-Day Vulnerabilities in Microsoft Exchange Server” for CVE-2022-41040 and CVE-2022-41082.
Analysts need a way to detect and respond to zero-day attacks prior to when vulnerabilities or compromises are known. Security professionals also need to quickly assess if compromise is likely once a zero-day vulnerability is known.
When it comes to the exploitation of Microsoft Exchange Server via a zero-day attack, knowing what MITRE ATT&CK techniques are used helps the analyst know what to look for during their threat hunt. We have written a lot about how MITRE ATT&CK helps in the detection and classification of attacks. You can read more about MITRE ATT&CK from LogRhythm here.
Part of responding to known cyberattacks requires security teams to focus on threat hunting within the environment for Indicators of Compromise (IOCs). LogRhythm Labs breaks down how to do this in detail in our blog, “How to Detect and Search for SolarWinds IOCs in LogRhythm.” To reduce risk, analysts need to quickly identify what is suspicious in their environment and determine if compromise is likely. The goal is to reduce mean time to detect (MTTD) and mean time to respond (MTTR) to cyberthreats.
Detecting Zero-Day Exploits with SIEM
When detecting Microsoft Exchange zero-day exploits, we advise you follow this general guidance:
- First, apply patches as soon as they become available.
- Assume compromise.
- Look for AI Engine events involving your Exchange infrastructure (Host Names, IPs, Privileged Users and Service Accounts) starting back in time to when the vulnerability or attack is known to the present.
- Use Indicators of Compromise (IOCs) and perform threat hunts.
- Review NextGen Firewall, Intrusion Detection Systems (IDS), EDR, and AV logs for suspicious activity starting back in time to when the vulnerability or attack is known to the present.
Detecting a zero-day vulnerability prior to it becoming public requires work upfront to make sure you have the visibility you need to detect suspicious activity. Once a zero-day exploit is announced, security teams also need to quickly assess if there is a compromise by using IOCs that have been published and searching retroactively.
You need to actively configure and collect application and system logs from any publicly accessible environments, as well as any system or application that has administrative rights to the environment. To demonstrate what type of logs you will need to collect, and how they are classified in LogRhythm, I will use a Microsoft Exchange Server as an example.
What Type of Logs to Collect from Microsoft Exchange
Here are the Log Sources typically found on an Exchange Server and the LogRhythm Log Source Types:
- LogRhythm SysMon
- LogRhythm Process Monitor (Windows)
- LogRhythm File Monitor (Windows)
- Microsoft Security Event Logs:
- MS Windows Event Logging XML – Security
- Microsoft Application Event Logs:
- MS Windows Event Logging XML – Application
- IIS Logs
- Flat File – Microsoft IIS W3C File
- Microsoft Sysmon
- MS Windows Event Logging XML – Sysmon
The LogRhythm Classification and Common Events that an analyst will most want to focus on are:
- Classification
- Audit/Authentication Success
- Audit/Account Created
- Audit/Configuration
- Ops/Error
- Security/Malware
- Security/Failed Malware
- Classification and Common Events
- Common Event: Audit/Startup and Shutdown AND Common Event: Process/Service Started
- Common Event: Access Success AND Common Event Object Modified
- Common Event: Access Success AND File Monitoring Event – Add
Based on the previous Microsoft Exchange Server Zero-Day compromise, a list of MITRE ATT&CK techniques was published by Microsoft and is a good set of techniques to pay attention to going forward to detect suspicious activity that could be a yet unknown Zero-Day. In LogRhythm, we have created a module of AI Engine rules that focus on the MITRE ATT&CK techniques and include the techniques listed by Microsoft. In LogRhythm, the AIE rule names are:
- T1059.001 : Command and Scripting Interpreter: PowerShell
- T1083 : File and Directory Discovery
- T1018 : Remote System Discovery
- T1082 : System Information Discovery
- T1003 : System Service Discovery
- T1021.002 : Remote Services: SMB/Windows Admin Shares
In this blog, I will use LogRhythm to demonstrate how an analyst can leverage MITRE ATT&CK techniques in an enterprise environment looking for suspicious activity that would apply to their Microsoft Exchange Server.
Below is a quick overview of the MITRE ATT&CK dashboard displaying many MITRE ATT&CK technique detections, also known as AI Engine events. We have developed a MITRE ATT&CK AI Engine module that identifies certain log activity as a specific MITRE ATT&CK technique. When AI Engine creates an event on these techniques, it populates the LogRhythm dashboard similar to the events.
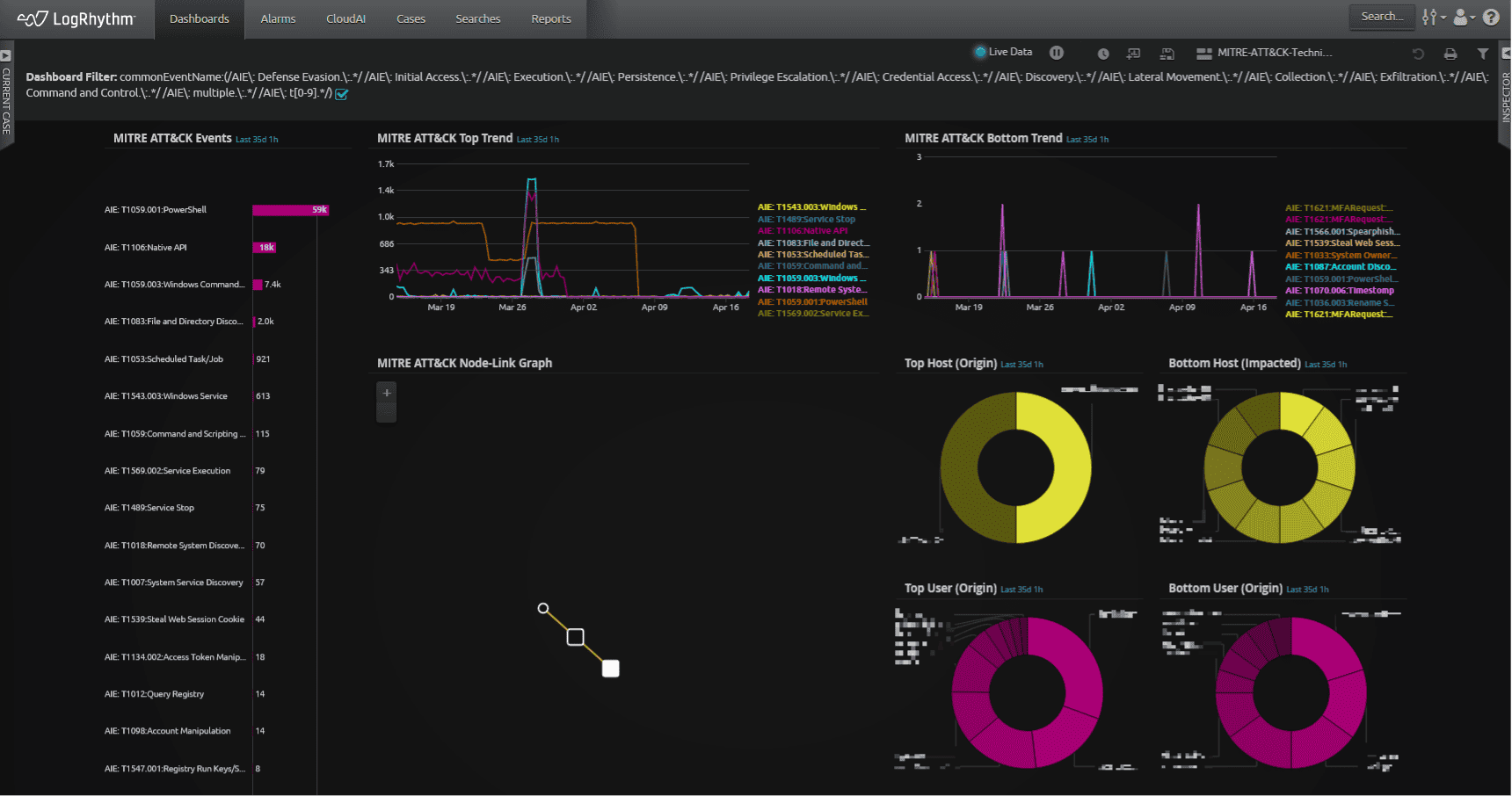
An analyst can use any number of the widgets to help identify suspicious techniques to investigate. Starting with the MITRE ATT&CK Events in the upper left, an analyst can choose to investigate the most frequent, or least frequent techniques as a starting point for example. Using the MITRE ATT&CK Top Trend or Bottom Trend widgets, an analyst can quickly see the events over time and identify patterns that might be worth investigating. Using the MITRE ATT&CK Node-Link Graph, an analyst can quickly visualize users and asset interactions. This feature is a good starting point for investigations. The analyst could also use the Host or User widgets to investigate activity based on the most observed techniques.
Using the dashboard is a fantastic way to start threat hunts and generally observe what the analyst may feel is suspicious activity to investigate. There is another method that an analyst can configure using the MITRE ATT&CK techniques to alert the analyst with more confidence that an attack or compromise is occurring. In the following example, I will demonstrate how the analyst can configure an AIE rule based on MITRE ATT&CK technique events that apply to a Microsoft Exchange Server compromise.
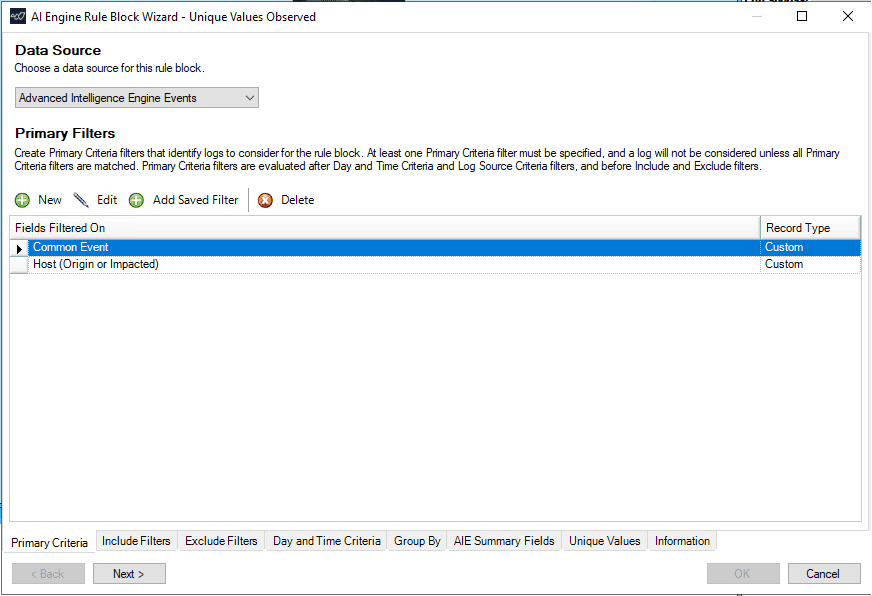
I will start with creating a Unique Values Observed rule in AIE using the AIE events as the data source. This will allow me to leverage the AIE events already being generated to feed into this new rule. I know the MITRE ATT&CK techniques observed from the previous Microsoft Exchange attacks, so I will use those techniques as part of my criteria in the new rule.
After selecting the AIE events in the primary criteria, I will also add a filter for my Microsoft Exchange server that is in scope for this new rule.
In the picture below, I now have the basic rule logic built for my new rule.
Next, I need to select the period during which all of the Common Events must be observed for the rule to trigger. It is likely that the events would be observed in less than an hour, so I will start with an hour as my timeframe in the picture below. Note, the rule does not need to wait for the full hour before it will event. The rule will event as soon as all the criteria is met within the hour. The time can easily be adjusted for more or less time in the future based on incident reports or observations. I will also set the number of unique occurrences to the number of MITRE ATT&CK techniques that would need to event to be considered for this new rule to event. From earlier, there are six MITRE ATT&CK techniques that were identified by Microsoft.
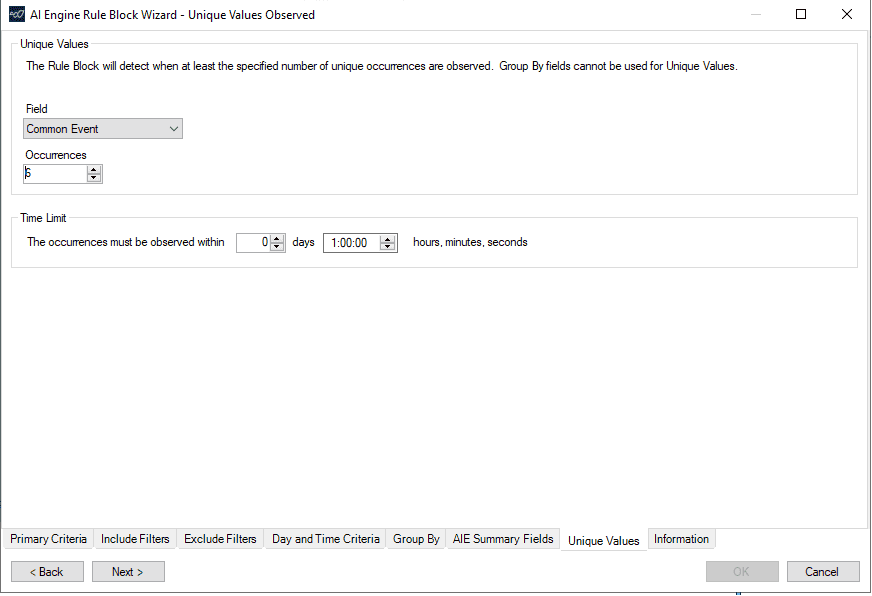
There are some other general settings I will need to configure to complete this rule which I will not show here.
Once the new AI Engine rule is enabled, I will configure a test using LogRhythm ECHO. You can read more about LogRhythm ECHO here. The ECHO use case is configured with a set of logs to cause the individual AI Engine events to event as shown in the picture below.
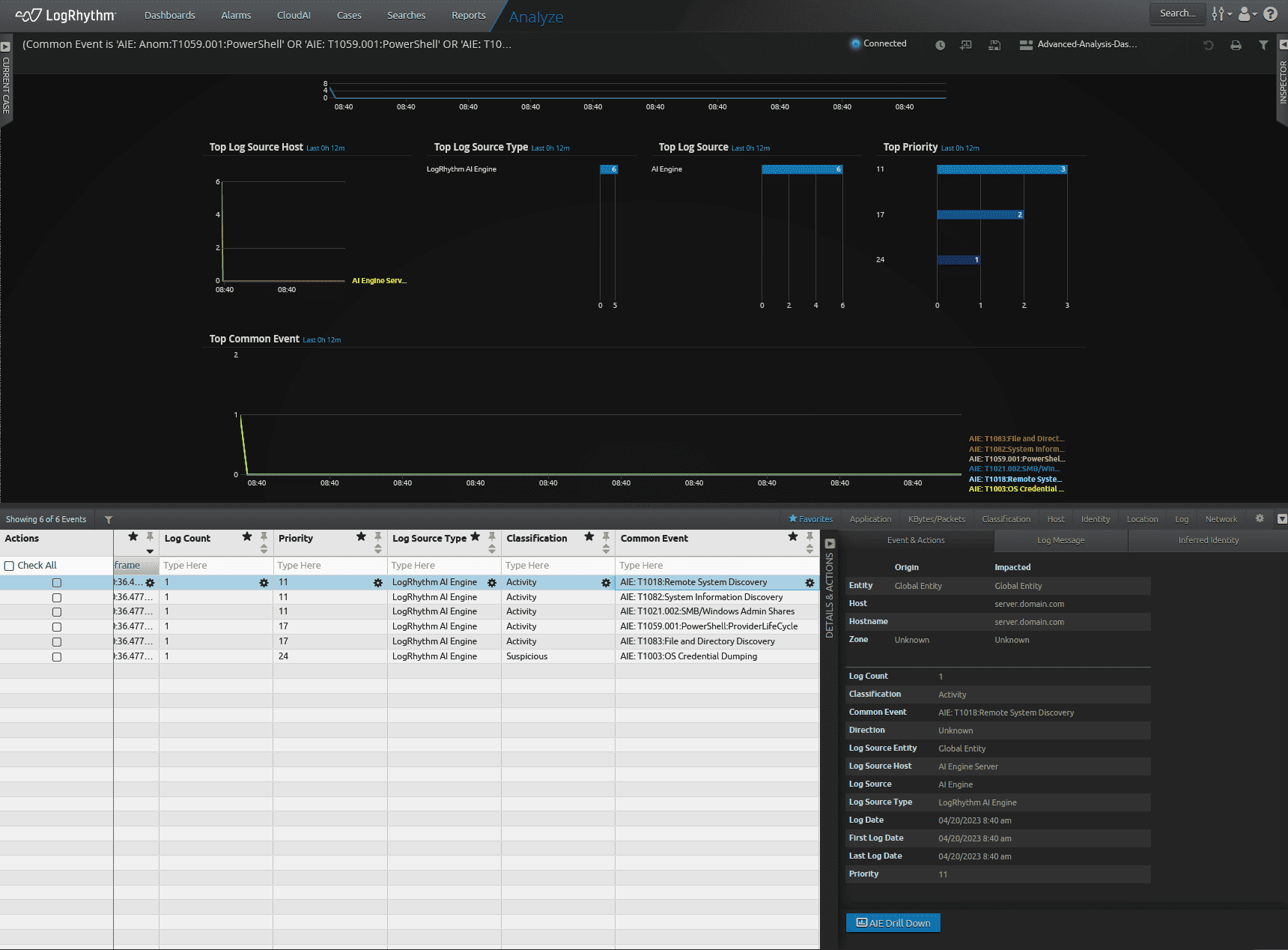
The new rule will see the individual technique events and will event indicating “Exchange Compromise” as in the picture below.
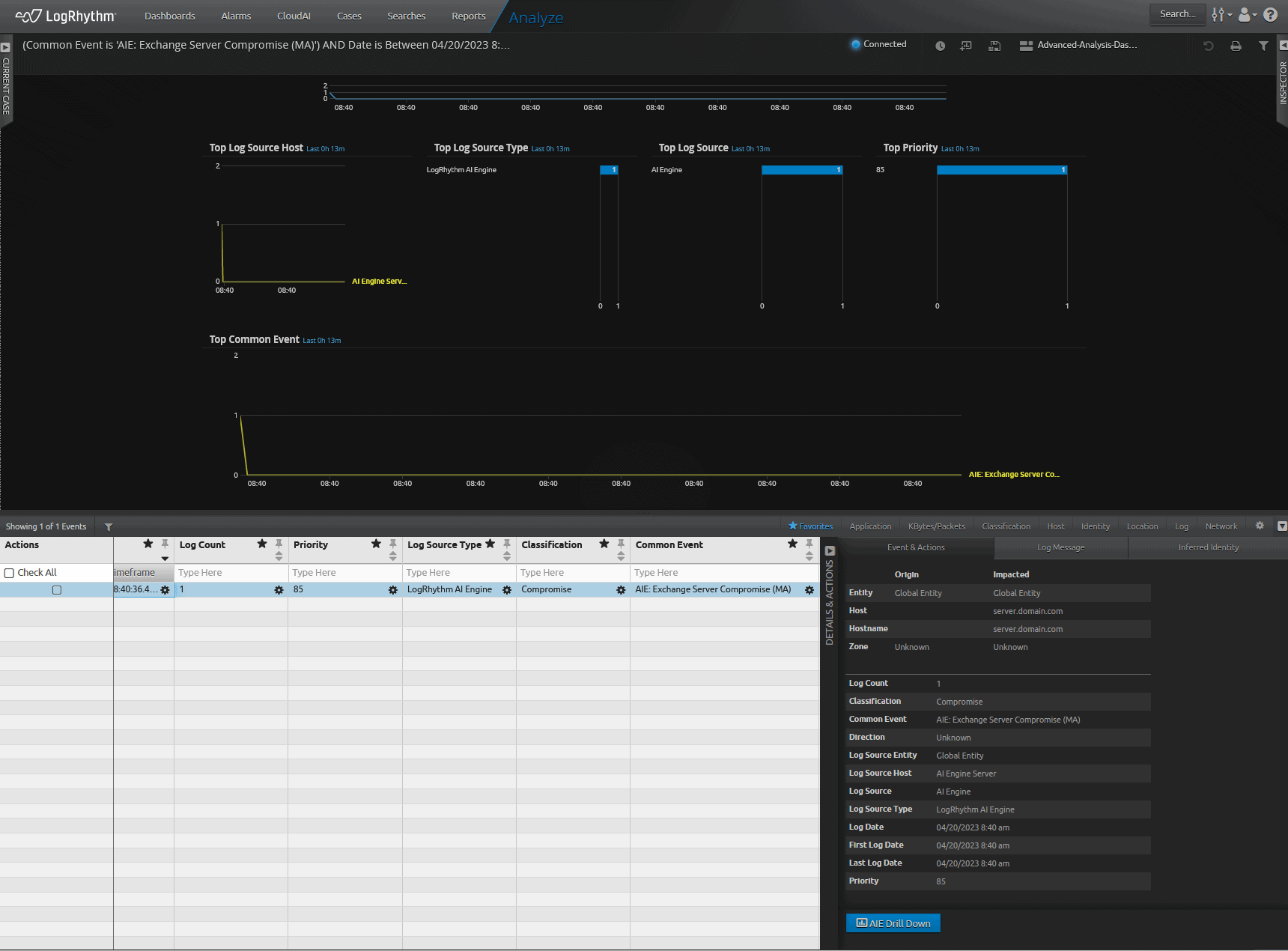
Conclusion
In summary, creating a combined MITRE ATT&CK technique-based event will create a highly effective event that will quickly alert an analyst to the Exchange Compromise. This method of combining relevant MITRE ATT&CK techniques into a new rule can be applied across the enterprise based on previous attacks and compromises within your organization or detecting possible attacks and compromises against your enterprise based on threat intelligence reports. This methodology of creating a rule that combines techniques together will help your enterprise detect and respond to zero-day exploits faster.


