We’ve heard you — onboarding log sources isn’t an easy task. You may have a lot of data to aggregate. Also, the data may be in various states and come from multiple users. Finally, it takes time to process logs, and time is always of the essence.
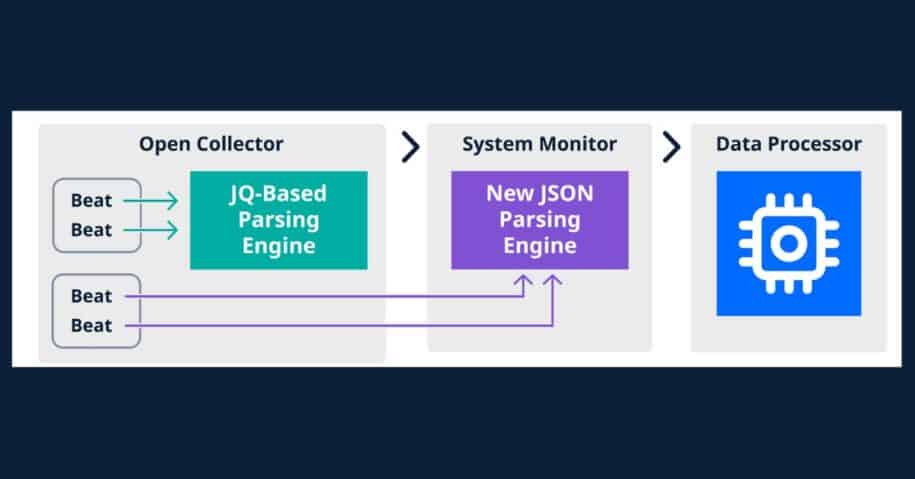
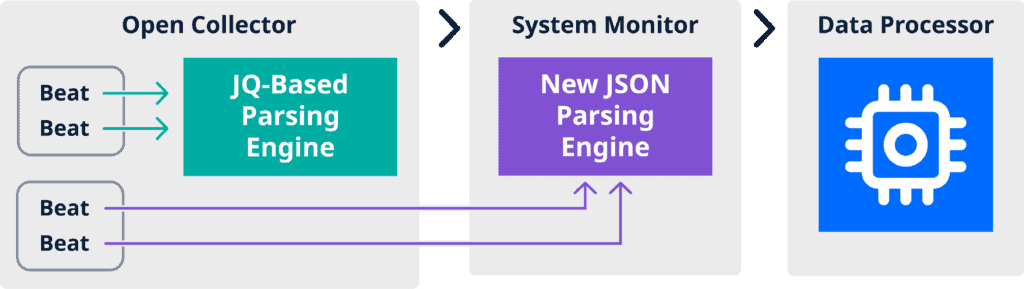
To ease log ingestion challenges, LogRhythm has made it easier to ingest cloud-native log sources by creating a new architecture in System Monitor, the SIEM’s collection tool. As part of the LogRhythm SIEM version 7.13 release, we’ve installed a new JSON parsing engine in SysMon that improves performance to simplify the user workflow.
Ingest Log Sources Faster
The new JSON parsing engine is the latest progression in LogRhythm’s collection technology that simplifies and accelerates log source collection for LogRhythm SIEM and LogRhythm Cloud customers.
With the new architecture, customers who download LogRhythm 7.13 can reroute their beats from the Open Collector parsing engine to the new parsing engine in SysMon. The new architecture enables you to ingest cloud-native log sources significantly faster, simplifying user workflows to onboard data.
The JSON parsing engine, which is capable of handling thousands of messages per second, brings cloud collection capabilities into the same workflow as existing non-cloud log sources, simplifying the user workflow to onboard data.
Easing the Workflow
Incorporating cloud collection capabilities as part of the same workflow as existing non-cloud log sources eases the work involved to onboard log sources, saving users time. The new engine also simplifies sizing, deployment, and troubleshooting of the platform.
No Need for Query Language
With the new engine, concerns about needing to learn JQ query language disappears. Now, users no longer need to rely on JQ language to define parsers. This allows for a simpler and more reliable mechanism to map log data to the LogRhythm schema. The JSON parsing engine also removes the need for two parsers per log source (one JQ for the Open Collector and one Machine Data Intelligence parser for the Data Processor). Read more in our data sheet.
Streamlining Log Collection
Our work to improve log collection isn’t done. In our next release, LogRhythm will focus on easing administration of log sources through the web console. To find out more about the latest updates in LogRhythm 7.13, read the blog post.